













 Peer architectures shatter the static computing roles used in approaches such as client/server. Devices in peer networks are called nodes. Some nodes provide services, and other nodes use those services. But the rules for which nodes perform which services vary depending on which scheme is being used.
Peer architectures shatter the static computing roles used in approaches such as client/server. Devices in peer networks are called nodes. Some nodes provide services, and other nodes use those services. But the rules for which nodes perform which services vary depending on which scheme is being used.
Think of the various tasks workers in a company must perform as “services.” How each company decides what tasks are performed by which employee varies widely, with some people asked to perform only one or two tasks while others are required to do many. That’s the way P2P works: Common functions in a peer network include registration and search (keeping track of users, devices and services), storing files, coordinating connections and communications, asking other nodes to perform certain tasks, failover, load-balancing, and relaying data such as names, links and content. Some peer schemes let all nodes perform all tasks, while others centralize some tasks to specific nodes.
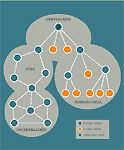
Centralized schemes look a lot like client/server systems. In a hierarchical approach, tasks ripple up and down a chain. Ring topologies balance tasks across multiple nodes. And decentralized schemes let all peers do all things.
Life gets really interesting when peer schemes blend these approaches. For example, a peer system may look hierarchical, but what appears to be a single server may actually be a distributed network of nodes dynamically banding together to act like a “virtual” server. The best mentality for understanding peer networks, then, is that all bets are off in terms of which nodes perform which tasks. The challenge for CIOs is to choose schemes that provide the best match for the kinds of services they want to provide end-users.